As the final phase of my database experiments, I’ve been playing recently with optimizing the speed of processing in the firehose process.
The Bluesky firehose is a streaming API that sends you every single thing happening on the network in real time – every post, like, follow, everything (encoded in a binary format called CBOR). And my firehose process is a client connecting to that stream, pulling data from it and saving the relevant parts (the posts).
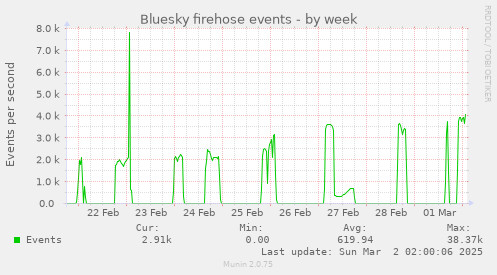
At the moment, the firehose flow ranges between ~300 and 700 events per second during the day (“event” being one “action” like created or deleted record of any kind), with the bottom around 7-9:00 UTC and the top around 17-22:00 UTC. But the highest bandwidth we’ve seen so far was around 1.8-2.0k events/s in mid November, when a massive new wave of new users joined in the aftermath of the US elections, and we’ve seen the traffic go up rapidly by a few hundred % within days before too, e.g. in early September when the whole Brazil joined Bluesky. The firehose protocol also includes a lot of extra data, needed for cryptographic verification and full replication of data repositories, but not used in a simple case like this – so the total data bandwidth to stream and process is an average ~20-30 Mbps right now (with the smaller traffic than before).
My server was struggling back then in November, processing the 1.8k events per second, which is a big part of the reason why I started looking for a better suited database than SQLite, to be able to handle the next wave. I had a few improvements lined up, which I now started applying one by one (trying to do one at a time, so I can measure which one does what difference), each time pausing the reading for a day or so, and then catching up for several hours at full speed, so I can check what’s the maximum speed it can do.
I was also doing very simple profiling on the way, measuring which parts take how much time and where I can still save some extra microseconds:

Overall, I managed to bring the number from around 2k evt/s to around 4k over a period of about a week (similarly in the MySQL and Postgres versions) – so not bad at all.
These are the changes I’ve made:
Partial indexes
I’ve switched two indexes in Postgres to partial indexes (MySQL doesn’t support that). I have two indexes in the posts table, on quote_id and thread_id, which set a reference to a quoted post and the root of the thread respectively, which are NULL for some of the posts (thread_id for like half of the posts, quote_id for the vast majority), so I added a WHERE ... IS NOT NULL condition to those two.
Effect: no noticeable change in performance, but it least the indexes take less space now.
ActiveRecord
I updated ActiveRecord – from v. 6.1 that I had before to 7.2 (Rails 8 was released in November, but it feels a bit too fresh right now). Ironically, AR 8.0 seems to finally fix my longstanding problem with concurrency errors in SQLite, just when I’m getting rid of it…
Effect: around +10% processing speed.
Ruby update + YJIT
I updated Ruby from 3.2 to 3.4 and enabled YJIT, a new optional JIT written in Rust. I had tested YJIT before on 3.2 and there was a noticeable improvement, but I’ve noticed some kind of memory leak then that they’ve apparently fixed only around 3.3.1. Interestingly, my code seems to run slightly slower on 3.3 and 3.4 without YJIT, but enabling it more than makes up for it.
Effect: around +15%.
Batch inserts
I was already previously grouping posts into a queue, waiting until I got 10, and then saving them all in one transaction, using code like this:
ActiveRecord::Base.transaction do
@post_queue.each do |p|
p.save!
end
end
This was already faster than the initial way of saving of each post separately, directly in the block where it’s built from the processed event. But that was still multiple INSERTs, and I wasn’t sure I could do it in just one while using the ORM.
Apparently I can, with the use of the insert_all API. The catch is that it takes an array of raw argument hashes, skips validations and doesn’t handle child records (my Post records have linked FeedPost entries if they are included in a feed). So I validate the records separately earlier (I was actually already validating them first before, which means the validations were running twice), and for those that have FeedPosts, I save them separately next.
So the whole thing looks like this:
def process_post(msg)
post = Post.new(...)
if !post.valid?
log "Error: post is invalid: ..."
return
end
@post_queue << post
if @post_queue.length >= POSTS_BATCH_SIZE
save_queued_posts
end
end
def save_queued_posts
matched, unmatched = @post_queue.partition { |x| !x.feed_posts.empty? }
if unmatched.length > 0
values = unmatched.map { |p| p.attributes.except('id') }
Post.insert_all(values)
end
@post_queue = matched
return if @post_queue.empty?
ActiveRecord::Base.transaction do
@post_queue.each do |p|
p.save!(validate: false)
end
end
@post_queue = []
rescue StandardError => e
# ... try to save valid posts one by one
end
Effect: up to around +30% in the Postgres version, less in MySQL one.
Rust native module for regex matching
Last year I wrote a little native module in Rust (which I didn’t know at all before) to speed up matching of post contents with a large number of regexps for the feeds:
I played with a benchmark of some regexp matching code in several languages last week (I wanted to replace that part of Ruby code with something faster, maybe Crystal or Swift). ChatGPT helped me write some versions :)
The results were… unexpected. Swift & Crystal didn’t do well, but JS & PHP did 🤔
[image or embed]
— Kuba Suder 🇵🇱🇺🇦 (@mackuba.eu) April 16, 2024 at 7:34 PM
I haven’t enabled it on production yet though, because there are some edge cases I need to get fixed, and I only used it for manual feed rebuilding so far. So as the next step, I enabled that Rust module in the firehose process. (I’d love to eventually make that available as a gem you can easily add to your app.)
Effect: +15%.
Asynchronous transaction commits
Next, I turned on two options: synchronous_commit = off in Postgres, and innodb-flush-log-at-trx-commit = 0 in MySQL. These basically make it so that when you commit a transaction, you don’t wait until it’s synced to disk first, but the request returns just leaving the data in memory, and the data is synced to disk later (but like, up to a second later). So if the whole instance hard-reboots for some reason, you can lose maybe one second of data (but it wouldn’t corrupt the database, since the transaction is either saved or not).
This is possibly still dangerous if you’re saving user’s private data from a webapp, but in this case, I’m streaming public data that I can scroll back through a bit if needed. So in the highly unlikely case that I lose a second of data somehow, I just replay a very slightly older cursor.
Effect: no noticeable improvement… probably because with the batched inserts, it was already doing just a few inserts per second, so there wasn’t any more time to save here.
Optimizing JSON handling and Time parsing
I had a place in the processing function where it encodes a record parsed from CBOR into JSON, to be saved into a data column and for logging purposes, but for complicated reasons that JSON.generate was called twice with slightly different versions of record. So I refactored that to let it skip one encode.
There was also some time spent parsing the record time and the event time into Time objects from an ISO8601 string using Time.parse; but I had a feeling that this could probably be speeded up using some native code, especially if it only accepts ISO8601 formats, and only in forms that actually appear in the data (since Time.parse handles many, many possible formats). With the help of Mr. GPT I made a little C module with a single function to replace Time.parse, and that indeed ended up being faster. (I’ll also try to turn that into a micro-gem.)
Effect: +8% (this finally pushed it over the 4k level)
Jetstream
Finally, just to check for now, I’ve switched from the full CBOR firehose to Jetstream, which is a kind of pre-processed stream that strips all the signatures and Merkle tree stuff and outputs a simplified JSON stream. I’ve already added support for it to my firehose library Skyfall in October, but I’m not using it everywhere yet.
Effect: +30-40%, although the speed was suspiciously capped at almost precisely ~4989 evt/s on both servers… so I’m guessing I might have hit some kind of rate limit of the Jetstream server. But I could also host it myself if needed.
(Edit: yes, apparently 5k is the default rate limit configured in Jetstream server settings.)
Potential ceiling
I also did a test with all processing completely skipped, so the app would just read the data packets from the websocket and discard them, not even decode the CBOR. This did around 6k evt/s with the full firehose (possibly more for Jetstream, but I couldn’t test this) – so it looks like this is the max I can do without switching to something completely different. The library I’m using for websocket connection uses the very old eventmachine library underneath, and I was told that the newer async-websocket that uses the Async framework could be faster, but in brief tests I wasn’t able to see any improvement so far.
Finally, just to see what the limit would be if I were to abandon Ruby (at least for that part), I ran a quick test in Rust, specifically using the example from the Atrium library. It did… 25k evt/s 😱 So yeah, there are still more options ;)
That said, my current VPS will max out the allowed traffic at a sustained 300 Mbps, which if I’m counting correctly would be something like 7.8k evt/s from the full firehose, so above that level this would be the main problem.



{kind=link}